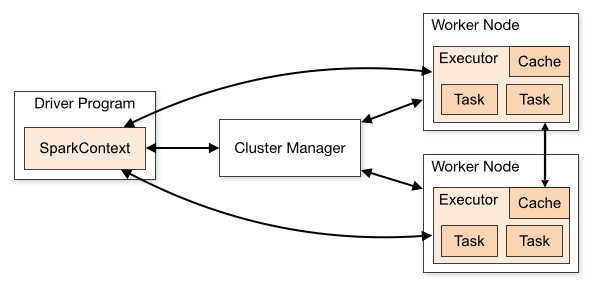
Spark 클러스터 설정/ 구축
1. 워커 노드에 SSH서버를 설치해서 마스터 노드에서 들어갈 수 있게 한다.
>sudo apt-get install oppenssh-server
2. 마스터 노드에서 키를 생성
> ssh-keygen
3. 워커 노드에 매번 비밀번호를 치고 들어가지 않게 하기 위해 RSA 키 복사
> ssh-copy-id -i ~/.ssh/id_rsa.pub user@x.x.x.x
4. conf 폴더에 slaves 템플릿을 복사해 파일 생성 워커 노드들을 잡아준다.

5. spark-env.sh도 템플릿을 복사해 파일을 생성한다.
export SPARK_MASTER_IP = N.N.N.N >>>>> 마스터 노드의 아이피
export SPARK_WORKER_CORES = 2 >>>>> 워커 노드의 사용 가능한 총 CPU 코어 수
export SPARK_WORKER_MEMORY = 2400m >>>>> 워커 노드의 전체 메로리 할당량
export SPARK_WORKER_INSTANCE =1 >>>>> 워커 노드의 프로세서 갯수

6. 마스터 노드의 커뮤터도 워커 노드에 추가해 활용하기
./bin/spark-calss org.apache.spark.deploy.worker.Worker spark://10.0.0.25:7077
7. 스파크 실행
MASTER=spark://10.0.0.25:7077 ./bin/pyspark
추후 실습을 다시 해서 추가내용으로 작성하도록 하자
'Data Engineer > Spark' 카테고리의 다른 글
| Spark SQL이란 ? (0) | 2016.05.12 |
|---|---|
| Spark - RDD란 !!? (2) (0) | 2016.05.09 |
| Spark - RDD란 !!? (0) | 2016.05.09 |
| Spark 설치 방법 (우분투 ubuntu 환경) (0) | 2016.05.09 |
| Spark - 클러스터 & 스택 구조 (0) | 2016.05.09 |