Spark Stream이란 ?
Real-time processing / Stream processing
- IOT 세상이 다가오면서 데이터의 크기도 중요하지만 속도도 부각
- 대량의 데이터를 빠르게 처리하기 위한 기술들이 실시간 처리 / 스트림 터리
- 실시간 처리는 데이터 처리의 목표 또는 제약 사항 방식 (마감 시각이 있다.)
- 스트림 처리는 데이터 처리 방식 (끊임없이 흘러가는 데이터에 대한 처리 방식)
Basic Concept

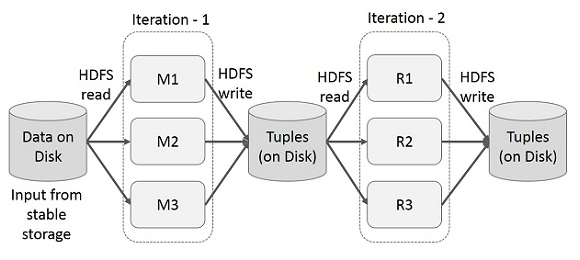
- 초 단위로 데이터 처리
- 마이크로 배치의 연속으로 구현 (DStream)
- kafkam Twitter, File System, TCP Socket 등등에서 데이터 수집
- RDD에 제공되는 Operation과 시간 기반의 Operation (예를 들면 sliding window)를 제공
Discretized System

- DStream이란 시간 흐름에 따른 순차적 데이터를 의미
- RDD 개념을 갖고 있는 Spark와 유사하게 Spark Streaming은 DStream 또는 Discretized Streams라고 불리는 추상 개념을 가지고 있다.
실습 예)
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
# StreamingContext 두개의 워킹 쓰레드와 5초 간격으로 정보 배치를 가지게 초기화
sc = SparkContext("local[2]", "NetworkWordCount") # spark://10.0.0.25:7077 로 클러스터도 연결 가능
ssc = StreamingContext(sc, 5)
# localhost:9999에 연결하는 정보로 DStream 생성
lines = ssc.socketTextStream("localhost", 9999)
# 매 라인을 단어로 스플릿
words = lines.flatMap(lambda line: line.split(" "))
# 배치 단위로 워드 카운트
pairs = words.map(lambda word: (word, 1))
wordCounts = pairs.reduceByKey(lambda x, y: x + y)
# 워드카운트 한 내용을 콘솔에 출력
wordCounts.print()
ssc.start() # 계산 실행
ssc.awaitTermination() # 계산이 에러나 명령에 의해 강제로 종료될 때까지 기다림
natcat 실행
(Network connection 에서 raw-data read, write를 할수 있는 유틸리티 프로그램)
nc -lk 9999
소스코드 실행
./spark/bin/spark-submit test.py localhost 9999
- StreamingContext가 시작되면 다른 StreamingContext는 실행되거나 추가될 수 없음
- StreamingContext가 종료되면 재시작 불가능
- 하나의 JVM에 하나의 StreamingContext만 가능
'Data Engineer > Spark' 카테고리의 다른 글
| Spark SQL이란 ? (0) | 2016.05.12 |
|---|---|
| Spark - RDD란 !!? (2) (0) | 2016.05.09 |
| Spark - RDD란 !!? (0) | 2016.05.09 |
| Spark - 클러스터 설정/ 구축 (1) | 2016.05.09 |
| Spark 설치 방법 (우분투 ubuntu 환경) (0) | 2016.05.09 |