리눅스의 ip체크 명령으로 지금까지 ifconfig를 사용해왔다.
ifconfig에서 interface 명과 ip값을 가져오려면 많은 생각을 해야 했는데
그러던 중 발견한 명령어
ip addr | grep "inet "
이걸 subprocess.popen으로 열어서 split 하면 값을 편하게 가져올 수 있었다.
리눅스의 ip체크 명령으로 지금까지 ifconfig를 사용해왔다.
ifconfig에서 interface 명과 ip값을 가져오려면 많은 생각을 해야 했는데
그러던 중 발견한 명령어
ip addr | grep "inet "
이걸 subprocess.popen으로 열어서 split 하면 값을 편하게 가져올 수 있었다.
RDD란?
RDD Operator
- Tranceformation : 데이터의 흐름, 계보를 만듬
- Action Transformation에서 작성된 계보를 따라 데이터 처리하여 결과를 생성함 (lazy-execution)
Actions == transformations의 결과를 가져오는 과정
선 디자인 후 연산이 시작된다 >>>>> 미리 계획이 되어 있었기 때문에 연산 속도가 매우 빠르다.
Narrow dependency / Wide dependency
Narrow dependency 형태로 코딩해야 한다.
- 책상 한자리에서 다 처리할 수 있는 일은 모아서 하는 것이 좋다는 개념
- 네트워크를 안타고 메모리의 속도로 동작해서 빠르다.
- 파티션이 부서져도 해당 노드에서 바로 복원 가능하다.
- map, filter, union, join with inputs co-partitioned
Wide dependency
- 여러 책상에 있는 자료를 훑어와야 한다는 개념
- 네트워크의 속도로 동작해서 느리다.
- 노드끼리 셔플이 일어나야 한다.
- 파티션이 부서지면 계산 비용이 비싸다.
- groupByKey, join with inputs not co-partitioned
>>>>dependency의 의미
메모리 안에서 처리 될 일들을 먼저 처리하고 네트워킹을 타거나 IO를 타는 일을 나중에 하도록 코딩을 해아한다는 의미.
네트워킹, IO시간을 메모리와 번갈아 가면서 구동하면 속도가 많이 느려지므로 최대한 메모리 내에서 할 수 있는 일을 한 후에 wide denpendency를 활용해야 한다는 의미.
RDD Persistence (더 학습이 필요..)
- RDD가 Action으로 수행될 때마다 다시금 소스에서 부터 다시 로드되서 수행됨.
- RDD를 저장해놓고 사용하는 기능으로 persist()와 cache()라는 두 가지 오퍼레이셔을 지원
- 저장 옵션을 MEMORY_ONLY로 한 옵션과 동일
- 디폴트는 메모리에 저장하고, 옵션으로 디스크를 지정
- 메모리에 저장할 때, RDD를 RAW(원본 형식)으로 저장할 것인지 자바의 Serialized(직렬화)된 형태로 저장할 지 선택
>>>오류 발생시 lineage의 맨 처음부터 수행하는 것이 아니라 중간 지점을 기억해 놓고 그 기억시점부터 다시 수행시키는 기술, 메모리를 사용하지만 속도가 더 빠른 것은 당연한 일
| Spark STREAM?? (0) | 2016.05.12 |
|---|---|
| Spark SQL이란 ? (0) | 2016.05.12 |
| Spark - RDD란 !!? (0) | 2016.05.09 |
| Spark - 클러스터 설정/ 구축 (1) | 2016.05.09 |
| Spark 설치 방법 (우분투 ubuntu 환경) (0) | 2016.05.09 |
RDD란?
spark에서 가장 핵심인 RDD에 대해서 알아보자.
사실 slideshare의 하용호 데이터사이언티스트님의 자료로 부터 많은 걸 얻을 수 있었다. 이 분의 자료는 실로 대단하고 또 쉽다. 나도 넘버웍스 인턴에 지원해보고 싶지만... 아직 부족한듯 하다.
무튼 참고자료
http://www.slideshare.net/yongho/rdd-paper-review?qid=3ff4fd97-e003-46c3-aeb9-dcc3977cdf0d&v=&b=&from_search=1
RDD란?
- 분산되어 있는 변경 불가능한 객체 모음(분산되어 존재하는 데이터 요소들의 모임)
- 스파크의 모든 작업은 새로운 RDD를 만들거나 존재하는 RDD를 변형하거나 결과 계산을 위해 RDD에서 연산(함수나 메소드)을 호출하는 것 중의 하나로 표현
Hadoop MapReduce의 단점?
> Machine Learning에 적합하지 않다.
> 데이터 처리시 HDFS(Hadoop Distributed File System)을 거치기 때문에 IO에서 시간이 오래 걸린다.
Spark는?
> RAM에서 Read-Only로 처리해서 running time이 빠르다.
Data Sharing is slow in MapReduce
- 맵리듀스들 사이에엇 데이터를 재사용하는 방법은 외부 안전한 스토리지 시스템에 데이터르 쓰는 방법뿐이다.
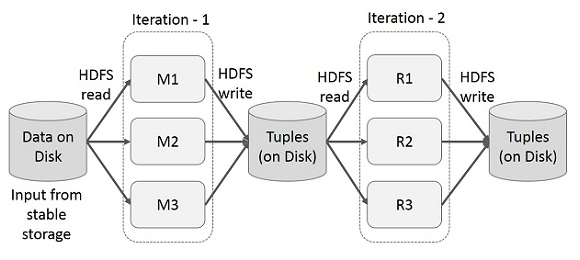
- 반복적이거나 Interactive 애플리케이션은 빠른 데이터 공유가 필요하다. 하지만 디스크 IO 응답시간, 직렬화시간 때문에 맵리듀스는 속도가 느리다. > 하둡 시스템에서 90% 이상의 시간이 HDFS로부터 데이터를 읽고 쓰는데 걸린다.
(하둡의 작동 방법 : 데이터를 찾아서(namednode에 질의) HDFS서 읽은 후 연산하고 그 결과를 로컬에 저장한 후 합쳐서 HDFS에서 다시 업로드 하는 방식)
Data Sharing using Spark RDD(Resilient Distributed Datasets)
- it supports in-memory processing computation. 작업 전체의 대상이 되는 메모리의 상태로 저장된다(Sharable)
> 네트워크나 디스크를 사용하는 것보다 10~100배 빠르다. >> 오류시 fault-tolerant 방식이 필요하다.(RAM에만 올려서 사용)
- immutable(read-only), partitioned collections of records
- 스토리지 >RDD변환 or RDD > RDD만 가능
##fault-tolerant 방식이란?
: 컴퓨터 시스템이란 시스템 내의 어느 한 부품 또는 어느 한 모듈에 Fault(장애)가 발생하더라도 시스템 운영에 전혀 지장을 주지 않도록 설계된 컴퓨터 시스템
- DAG (directed acyclic graph 디자인) > 코딩을 하는 것은 실제 계산 작업이 되는 것이 아니라 Lineage 계보를 디자인 해 가는 것 (빈 RDD를 만든다.)
일의 순서대로 빈 RDD를 만들어 가다가 가장 마지막 일이 수행되었을 때, 실제 일을 시작함
> Lazy execution의 개념이 여기서 나옴 - 일을 미루다가 나중에 한 방에 처리
| Spark SQL이란 ? (0) | 2016.05.12 |
|---|---|
| Spark - RDD란 !!? (2) (0) | 2016.05.09 |
| Spark - 클러스터 설정/ 구축 (1) | 2016.05.09 |
| Spark 설치 방법 (우분투 ubuntu 환경) (0) | 2016.05.09 |
| Spark - 클러스터 & 스택 구조 (0) | 2016.05.09 |