Spark 클러스터 구조
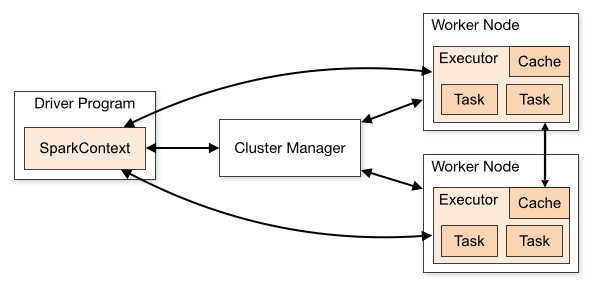
1. Driver Program : 스파크 프로그램. 여러 개의 병렬적 작업으로 나눠져 Worker Node에 있는 Executor에서 실행
2. SparkCotext : 메인 시작 지점. 스파크API를 활용하기 위해 필요하다. 클러스터의 연결을 보여주고 RDD를 만드는데 사용
3. Cluster Manager : Standalone, YARN. Mesos 등 클러스터 자원 관리자
4. Worker Node : 하드웨어 서버. 하나의 물리적 장치에 여러 개도 가능
5. Executer : 프로세스. 하나의 워커 노드에 여러 개 가능
Spark 스택 구조

1. 인프라 계층 (Standalone Scheduler, YARN, Mesos) : 먼저 스파크가 기동하기 위한 인프라는 스파크가 독립적으로 기동할 수 있는 Standalone, 하둡 종합 플랫폼인 YARN 또는 Docker 가상화 플랫폼인 Mesos 위에서 기동한다.
2. 스파크 코어 (Spark Core) : 메모리 기반의 분산 클러스터 컴퓨팅 환경인 스팍 코어가 그 위에 올라간다.
3. 스파크 라이브러리 : 스파크 코어를 이용하여 특정한 기능에 목적이 맞추어진 각각의 라이브러리가 돌아간다. 빅데이터를 SQL로 핸들링할 수 있게 해주는 Spark SQL, 실시간으로 들어오는 데이터에 대한 real-time streaming 처리를 해주는 Spark Streaming, 그리고 머신러닝을 위한 MLib, 그래프 데이터 프로세싱이 가능한 GraphX등이 있다.
'Data Engineer > Spark' 카테고리의 다른 글
| Spark SQL이란 ? (0) | 2016.05.12 |
|---|---|
| Spark - RDD란 !!? (2) (0) | 2016.05.09 |
| Spark - RDD란 !!? (0) | 2016.05.09 |
| Spark - 클러스터 설정/ 구축 (1) | 2016.05.09 |
| Spark 설치 방법 (우분투 ubuntu 환경) (0) | 2016.05.09 |